
Im Rahmen der Nachhaltigkeitsinitative fand ich es wichtig, zunächst den Ist-Zustand zu erfassen und so auch den Stromverbrauch am Institut zu ermitteln.
Bei zahlreichen Servern wird regelmäßig mittels IPMI der Stromverbrauch (genauer: die Leitung der Netzteile) abgefragt. Dies wird u.a. durch Munin umgesetzt. Munin läuft dabei auf jedem Gerät, fragt regelmäßig die Werte ab und speichert diese in einer Zeitreihen-Datenbank. Dazu nutzt Munin das RRDtool. Ein zentraler Server holt in größeren Abständen diese Zeitreihen und speichert sie lokal.
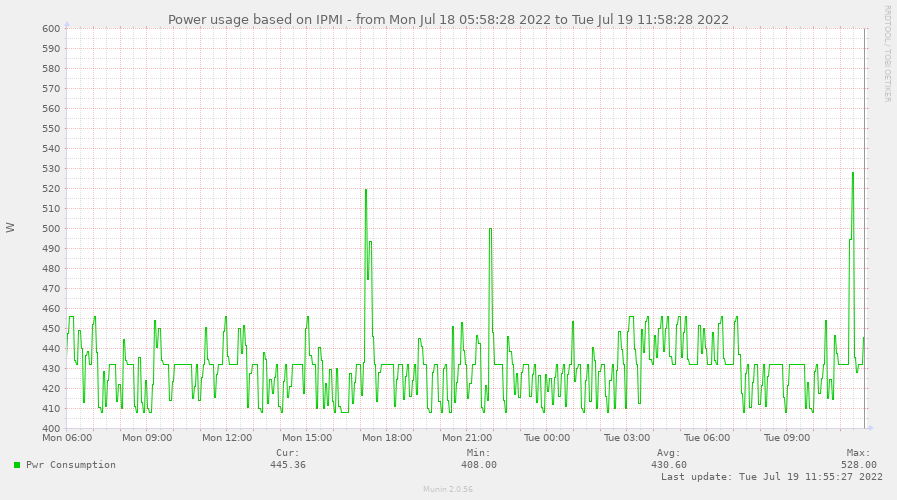
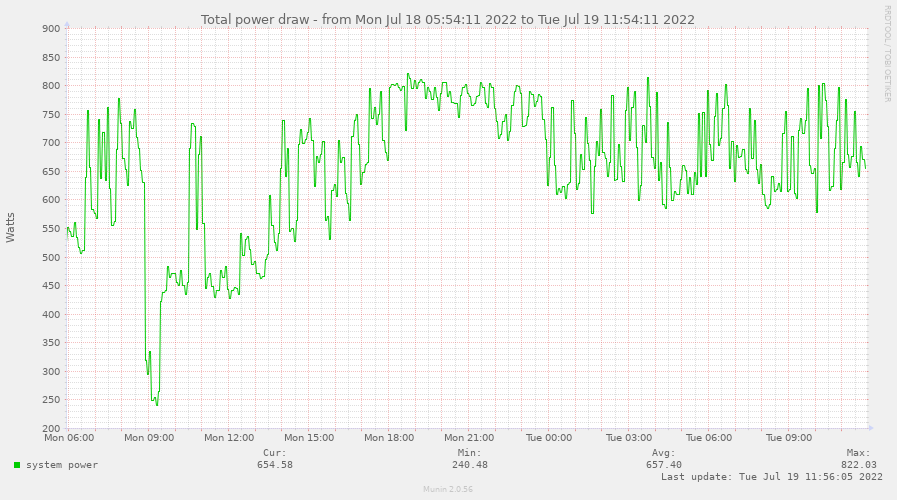
Diese Zeitreihen zu den Leistungen wird nun auch wieder mit Munin zu einer Gesamtleitung zusammengefügt.
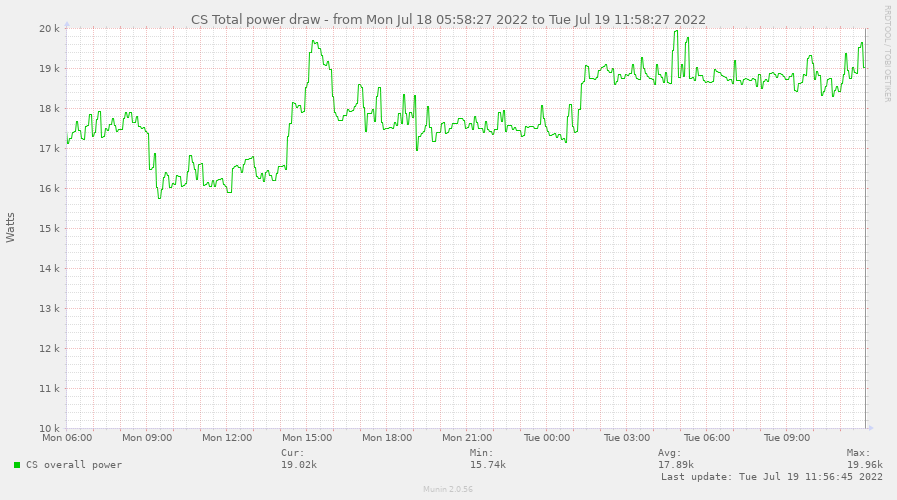
Mittels der Gesamtleistung als Zeitreihe wird der Gesamtverbrauch ermittelt und visualisiert.
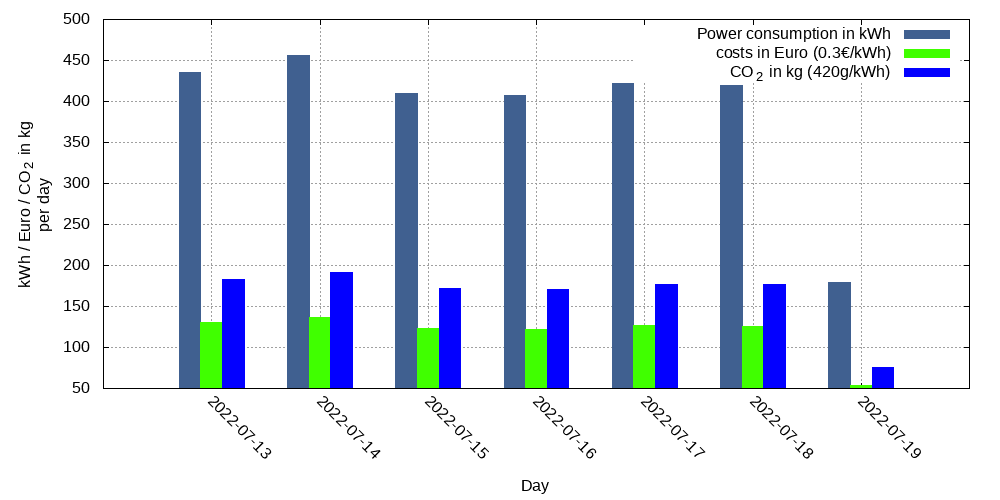
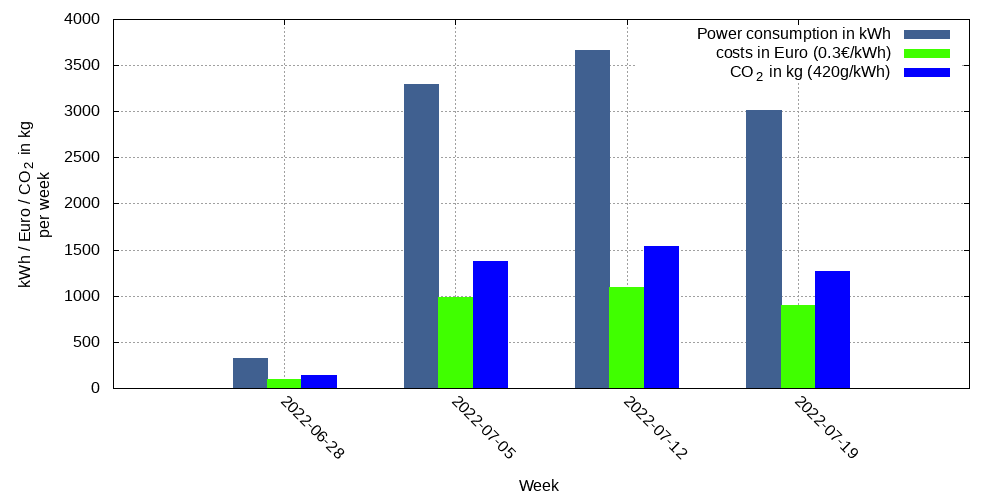
Wichtig ist dabei zu wissen, dass noch nicht alle Server erfasst werden. Des weiteren fehlt auch der Stromverbrauch der Infrastruktur wie Netzwerk und Klimaanlagen. Der tatsächlich Stromverbrauch liegt also deutlich höher.
Aktuelle Diagramme
Auf den Seiten der Rechnerbetriebsgruppe werden die aktuellen Werte veröffentlicht und regelmäßig aktualisiert: Stromverbrauch der Informatik
Am Institut für Informatik werden 2 GlusterFS-System mit jeweils verschiedenen Volumes betrieben. Daneben gibt es noch Fileserver, die über NFS eingebunden werden. Im folgenden soll nun die Performance der unterschiedlichen Systeme evaluiert werden.
Vorab-Test
Um grob die Lese uns Schreibperformance der einzelnen Dateisysteme vergleichen zu können, soll ein großes tar-File (gcc-9.4.tar.gz) in das Dateisystem entpackt (Write) und danach von dort wieder gepackt werden (Read).
Das tar lag unter /dev/shm (RAM), um den Einfluss beim Lesen und Schreiben zu reduzieren.
- Write: time tar xfz /dev/shm/gcc-9.4.0.tar.gz
- Read: time tar cf /dev/shm/gcc-9.4.0-test.tar gcc-9.4.0/
Die Tests erfolgen von 3 verschiedenen Systemen aus:
- Dell OptiPlex7040 (Teil des Pool-GlusterFS): 32GB RAM, Intel Core i7-6700 CPU @ 3.40GHz, 1GBit/s
- Dell PowerEdge 740xd: 756GB RAM, Intel Xeon Gold 6254 CPU @ 3.10GHz, 10GBit/s
- Dell PowerEdge 920: 1024GB RAM, Intel Xeon CPU E7-4880 v2 @ 2.50GHz, 10GBit/s
Ergebnisse
| Dateisystem | Typ | Write | Read |
| /home/tmp (lokal) | ext4 | 4s 3,7s x | 9s 5,3s x |
| $HOME | nfs | 110s x x | 114s x x |
| /vol/tmp | nfs | 106s x x | 82s x x |
| /vol/pool-tmp | nfs (2 x 10GBit/s) | 58s 42s x | 48s 38s x |
| /glusterfs/pool-gfs-dist | glusterfs | 311s* / 96s** 85s x | 139s* / 56s** 50s x |
| /glusterfs/pool-gfs-dist_repl_3 | glusterfs | 740s* / 218s** x x | 346s* / 130s** x x |
| /glusterfs/dfs-gfs-dist | glusterfs | 92s 96s x | 62s 54s x |
| /glusterfs/dfs-gfs-dist_repl_2 | glusterfs | 197s x x | 101s x x |
In dem Blog-Beitrag „TensorFlow selbst gebastelt“ wurde die Kompilierung und Installation von Tensorflow 1.15 mit CUDA-Unterstützung für CUDA-10 beschrieben. Mittlerweile ist CUDA in der Version 11 angekommen und Tensorflow gibt es in der Version 2.3.0: Ein Update ist also nötig!
Das Vorgehen ist relativ ähnlich zum vorherigen Beitrag. Die erste große Hürde ist Bazel. Zum Einsatz kam eine vorkompilierte Version (3.2.0) von github:
cd ~ ; wget https://github.com/bazelbuild/bazel/releases/download/3.2.0/bazel-3.2.0-linux-x86_64
Danach wurde tensorflow von github herruntergeladen:
- git clone https://github.com/tensorflow/tensorflow.git
- cd tensorflow/
- git tag
- git checkout tags/v2.3.0 -b v2.3.0-branch
- ./configure
Nun wird die gewünschte Konfiguration abgefragt:
- /usr/bin/python3 (Default-Wert)
- /usr/lib/python3.6/site-packages (Default-Wert)
- n (OpenCL SYCL)
- n (ROCm)
- y (CUDA)
- n (TensorRT)
- 11 (CUDA-Version)
- 8 (cuDNN-Version)
- (leere Eingabe) (ncc)
/usr/,/usr/include/,/usr/local/cuda-11.0/,/usr/local/cuda-11.0/include/,/opt/cuda/include/,/opt/cuda/lib64- 7.0 (compute cap)
- n
- /usr/bin/gcc (Default-Wert)
-D_GLIBCXX_USE_CXX11_ABI=0 -O3 -Wformat -Wformat-security -fstack-protector -fPIC -march=native -Wno-sign-compare- n
Die Konfiguration ist fertig – jetzt das Bauen mit dem Bazel von github:
../bazel-3.2.0-linux-x86_64 build –config=opt –config=numa –config=cuda –config=mkl –config=monolithic –config=v2 //tensorflow/tools/pip_package:build_pip_package
Jetzt lange Warten ….. und dann das Paket schnüren:
bazel-bin/tensorflow/tools/pip_package/build_pip_package tensorflow_pkg
Die fertige whl-Datei liegt nun unter tensorflow_pkg und kann nun installiert werden:
pip3 install -I tensorflow_pkg/tensorflow-2.3.0-cp36-cp36m-linux_x86_64.whl
pip3 list | grep tensorflow
Informationen für die NutzerInnen des Instituts für Informatik:
Auf gruenau9 und gruenau10 kann das pip-Paket wie folgt installiert werden:
pip3 install --force-reinstall /vol/pool-software/tensorflow/gruenau9_10/tensorflow-2.3.0-cp36-cp36m-linux_x86_64.whl
Um CUDA nutzen zu können, müssen die entsprechenden Treiber für die NVIDIA-GPU und die Bibliotheken installiert sein. Unter OpenSuse 15.2 kann man die entsprechenden Repositories hinzufügen:
- NVIDIA-Treiber: https://download.nvidia.com/opensuse/leap/15.2
- CUDA: http://developer.download.nvidia.com/compute/cuda/repos/opensuse15/x86_64
Danach müssen folgende Pakete installiert werden:
- cuda-11-0
- nvidia-computeG04 (Repo: cuda)
- nvidia-computeG05 (Repo: NVIDIA)
Um ältere Binaries zu unterstützen, die gegen ältere CUDA-Bibliotheken gelinkt sind, können noch folgende Pakete installiert werden:
- cuda-10-0
- cuda-10-1
- cuda-10-2
Nach der Installation und ggf. einem Neustart kann mit dem Kommando „nvidia-smi“ alles geprüft werden.
Zur GPU-Unterstützung für Deep Neural Networks sollte NVIDIA cuDNN installiert werden. Die Bibliothek kann von der NVIDIA-Webseite in verschiedenen Versionen heruntergeladen werden:
- cudnn-7.4.2
- cudnn-7.6.5
- cudnn-8.0.x
Die verschiedenen Versionen sind ggf. nötig, falls vorkompilierte Bibliotheken zum Einsatz kommen, die gegen eine bestimmte Major o. Minor-Version gelinkt sind.
Linkliste:
Bei fehlerhaften oder abgestürzten X-Anwendungen kommt es zu sehr vielen Eintragen in der Datei .xsession-errors – insbesondere wenn die Session lange läuft.
Damit die Nutzer nicht das Home-Verzeichnis bzw. das Netzwerk-/SAN-Laufwerk vollschreiben (2TB hatten wir schon), haben wir das Loggen deaktiviert. Unter OpenSuse war folgendes nötig:
Unter /etc/X11/xinit/xinitrc.d/ wurde die Datei 05-noerrfile mit folgendem Inhalt angelegt:
#!/bin/sh
# This is a -*- shell-script -*- fragment called by /etc/X11/Xsession
# Redirect all errors to /dev/null instead of $ERRFILE
# (~/.xsession-errors by default), to avoid filling up users home
# directory with error messages. Allow the user to disable this by
# creating ~/.xsession-errors-enable
if [ ! -f "$HOME/.xsession-errors-enable" ] ; then
rm -f $HOME/.xsession-errors
ln -s /dev/null $HOME/.xsession-errors
# Report the change to the log file before switching
echo "info: Redirecting xsession messages to /dev/null."
echo "info: touch '$HOME/.xsession-errors-enable' to disable this."
exec >> /dev/null 2>&1
fi
Die Rechte der Datei müssen angepasst werden:
chmod 755 /etc/X11/xinit/xinitrc.d/05-noerrfileSobald sich der Nutzer nun einloggt, zeigt der Link .xsession-errors nach /dev/null.
Auf den Server und PCs ist u.a. das TensorFlow-Paket für Python 2 & 3 installiert. Für GPU und MKL gibt es jeweils spezielle Pakete. Verschiedene Features (z.B. AVX512-Instruktionen von neueren Intel-CPUs) werden jedoch nicht unterstützt. Ich habe deshalb TensorFlow 1.15 (TF) für die einzelnen Systeme am Institut gebaut. TF gibt es mittlerweile auch in der Version 2.0 jedoch ist die API stark verändert worden, weshalb sie nicht genutzt wurde.
Ich habe die Systeme am Institut wie folgt gruppiert:
| Gruppe | Architektur | CUDA | SyCL | MKL | NUMA |
| OptiPlex3060 | Coffee Lake | No | No | Yes | No |
| OptiPlex7040 | Skylake | 10.1 | No | Yes | No |
| gruenau | Clovertown | No | No | Yes | No |
| gruenau1 | Sandy Bridge | No | No | Yes | Yes |
| gruenau[2-4] | Skylake | No | No | Yes | Yes |
| gruenau[5-8] | Ivy Bridge | No | No | Yes | Yes |
| gruenau9 | Skylake | 10.1 | No | Yes | Yes |
Beim Bauen von TF aus den Quellen habe ich mich grob an [1] & [2] orientiert. Die Schritte sind dann mit Python 3, CUDA und MKL (z.B. gruenau9):
- git clone https://github.com/tensorflow/tensorflow.git
- cd tensorflow
- git fetch –all –tags –prune
- git checkout tags/v1.15.0-rc3 -b r1.15
- source /usr/local/lib/bazel/bin/bazel-complete.bash
- ./configure
Nun wird die gewünschte Konfiguration abgefragt. Meine Eingaben waren:
/usr/bin/python3/usr/lib/python3.6/site-packagesynnyn10.17.4.2(leere Eingabe)/usr/,/usr/include/,/usr/local/cuda-10.1/,/usr/local/cuda-10.1/include/,/opt/cuda/include/,/opt/cuda/lib64(leere Eingabe) -> Übernahme von Default-Wertn/usr/bin/gcc-6n-D_GLIBCXX_USE_CXX11_ABI=0 -O3 -Wformat -Wformat-security -fstack-protector -fPIC -march=native -Wno-sign-comparen
Die Konfiguration ist fertig – jetzt das Bauen:
bazel build --config=opt --config=numa --config=cuda --config=mkl --config=monolithic //tensorflow/tools/pip_package:build_pip_package
Jetzt lange Warten ….. und dann das Paket schnüren:
bazel-bin/tensorflow/tools/pip_package/build_pip_package tensorflow_pkg
Die fertige whl-Datei liegt nun unter tensorflow_pkg und kann nun installiert werden:
pip3 install -I tensorflow_pkg/tensorflow-1.15.0rc3-cp36-cp36m-linux_x86_64.whl
pip3 list | grep tensorflow
Für die einzelnen Gruppen waren sowohl die Angaben bei der Konfiguration anders (CUDA ja/nein?) als auch beim Bauen (–config=cuda & –config=numa den Maschinen entsprechend).
Wenn Hardware-Raid-controller nicht vorhanden sind oder nicht ausreichend vom System unterstützt werden, sind Software-Raids eine gute Alternative. Ein Vorteil dabei ist, dass bei jedem System und bei jeder Raid-Variante, die gleichen Tools und Kommandos zum Einsatz kommen.
Hier soll es nun um die Wiederherstellung eines Raid1 aus 2 Platten nach einen Ausfall gehen. Los geht es meist mit Lesefehler.
#> dmesg
25704.754673 print_req_error: I/O error, dev sdc, sector 976912
25704.754885 md: super_written gets error=10
25704.755024 md/raid1:md0: Disk failure on sdc2, disabling device.
md/raid1:md0: Operation continuing on 1 devices.
Über das Proc-FS kann man nun mehr Details über den Zustand des Raids bekommen.
#> cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdb2[0] sdc2[1](F)
142748672 blocks super 1.2 [2/1] [U_]
bitmap: 1/2 pages [4KB], 65536KB chunk
Die Platte /dev/sdc2 ist als fehlerhaft markiert (F) und muss ersetzt werden. Dazu muss sie zunächst aus dem Raid genommen werden.
#> mdadm /dev/md0 --remove /dev/sdc2
mdadm: hot removed /dev/sdc2 from /dev/md0
#> cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdb2[0]
142748672 blocks super 1.2 [2/1] [U_]
bitmap: 1/2 pages [4KB], 65536KB chunk
Die defekte Platte kann nun entfernt werden und durch eine neue Platte mit gleicher Größe ersetzt werden. Diese muss nun erkannt werden (SCSI-Bus scannen und Partitionstabelle einlesen).
#> rescan-scsi-bus
#> partprobe
Falls die Partitionen der beiden Platten nicht übereinstimmen, kann man die Partitionstabelle von der bestehenden Platte kopieren. Danach muss diese wieder neu eingelesen werden.
#> sfdisk -d /dev/sdb | sfdisk /dev/sdc
#> partprobe
Nun kann die neue Platte (Partition) wieder zum Raid hinzugefügt werden.
#> mdadm /dev/md0 --manage --add /dev/sdc2
#> cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md0 : active raid1 sdc2[2] sdb2[0]
142748672 blocks super 1.2 [2/1] [U_]
[=================>...] recovery = 86.1% (123025920/142748672) finish=7.0min speed=46830K/sec
bitmap: 0/2 pages [0KB], 65536KB chunk
Und weiter geht’s!
Das Programm zum Workshop findet man auf den Seiten des CMS. Ein Schwerpunkt ist „Räume, Ausstattung und Medientechnik“. Das CMS und die Technische Abteilung (TA) haben technische Richtlinien erarbeitet und eine Umfrage zu didaktischen Szenarien gemacht. Es entstand daraus der 3. AG DLI Report.
Herr Pirr ruft zum Mitwirken bei der AG DLI auf. Es gibt einen entsprechenden Moodle-Kurs. Man soll bei Interesse eine Mail an Herrn Pirr schicken.
Die wichtigsten Punkte des Workshops zusammengefasst:
- AG DLI erarbeitet Richtlinien zur Medienausstattung von Lehrräumen
- Zentrale Beschaffung, Wartung und Support in Bezug auf Medientechnik (MT) wird von einigen Teilnehmern gefordert
- Vorschläge für einfachere Handhabung der MT, Information zu Ansprechpartnern und Anleitungen zur MT wurden diskutiert
Nvidias CUDA bietet die Möglichkeit, GPU von Nvdia zu programmieren und zum Rechen zu nutzen. Darauf bauen viele weitere Technologien, Bibliotheken, Frameworks etc. auf. Dazu zählen u.a. OpenCL und Tensorflow.
Am Institut für Informatik sind zum Einen zwei PC-Pools (Berlin, Brandenburg) und ein Server (gruenau9) mit Nvidia-Karten ausgestattet (Geforce 750GTX bzw. TeslaV100).
Im Rahmen von Lehrveranstaltungen ist es durchaus sinnvoll kleine Videos zu erstellen, die bestimmte Abläufe zeigen: Bilder sagen mehr als 1000 Worte.
Das Tool recordmydesktop bietet diesbezüglich die Möglichkeit den gesamten Desktop, Teile davon oder einzelne Fenster als Video aufzunehmen.
Beispiel:
recordmydesktop --fps 6 --width 1120 --height 630
Um einzelne Fenster aufzunehmen, muss die Window-ID benutzt werden. Diese lässt sich bequem über xwininfo ermitteln.
WINDOW_ID=xwininfo -display $DISPLAY | grep 'id: 0x' | grep -Eo '0x[a-z0-9]+'
recordmydesktop --windowid $WINDOW_ID --on-the-fly-encoding --v_quality 50 --s_quality 10 -o outfile.ogv
Beides zusammen gibt es als Skript auf den Linux-Rechnern des Instituts:
record_window.sh [outfile-name]
Nach dem Aufruf muss man das gewünschte Fenster wählen und startet damit auch die Aufnahme. Durch Strg+C wird die Aufnahme beendet. Die Aufnahme wird unter record.ogv abgelegt. Der Dateinahme kann dem Skript mitgegeben werden.
Das dort erstellte Video:
