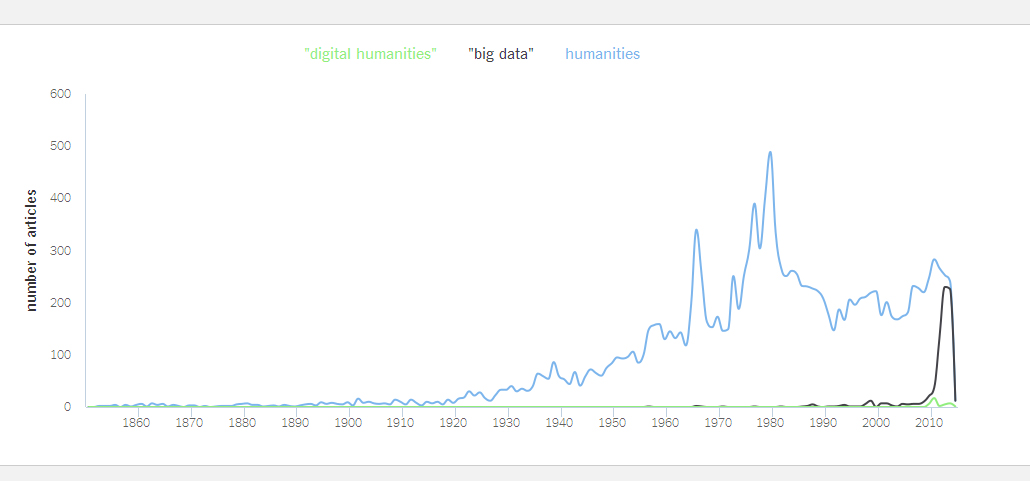
Das Jahr 2014 wird man vielleicht als das Jahr notieren, in dem in der öffentlichen Berichterstattung das Thema „Big Data“ fast mit den „Humanities“ gleichzog. Jedenfalls im Artikelaufkommen der New York Times.
Sichtbar wird das mit NYT Chronicle-Tool der nytlabs, das sich ganz gut zum Nachzeichnen von Themenkarrieren im Artikelaufkommen der Zeitung eignet. Ausgezählt lag „Big Data“ 2014 bei 226 Artikeln, die Humanities kamen auf 241 Artikel. Für die „Digital Humanities“ kommt man nur auf äußerst kleine Zahl (n=7). Die Ergebnisaussage zeigt dann auch gleich die derzeitigen Grenzen des Werkzeugs auf: Während die graphische Darstellung sieben Artikel vermerkt, werden die „Digital Humanities“ in der Ergebnisanzeige offenbar mit den Humanities zusammengewürfelt und stehen bei ebenfalls 241.
Schaut man sich die verlinkten Beiträge an, sieht man, dass die tatsächlichen Ergebnisse nicht gerade präzise und nach Relevanz aufgeschlüsselt vorliegen. Man muss den Umweg über die Standardsuche gehen, um auf die sieben Artikel im Publikationszeitraum 2014 bei der New York Times zu stoßen. Das ist ein bisschen schade, wäre doch die Möglichkeit, die Visualisierung als die Volltextsuche ergänzendes Navigationswerkzeug nutzen zu können, sehr nahliegend. Der Labs-Ansatz mit Werkzeugen zur Visualisierung, Kontextualisierung und Kuratierung (zum Beispiel mit dem Compendium-Tool) von Pressedaten veranschaulicht ja gerade, wie Datenjournalismus auch auf eine (Inter)Aktivierung der Leser hinführt, die perspektivisch mehr als mit der begrenzten Funktionalität der Leserkommentare auf die diskursive, also über Journalismus vermittelte bzw. durch diesen koordinierte wirklich öffentliche Auseinandersetzung mit Themen setzen könnte.
Die über die Archivsuche ermittelten Texte sind dann durchaus relevant und vermitteln zugleich, dass der Schlüsselbegriff im öffentlichen Diskurs jedenfalls bei der New York Times bisher nur eine Randexistenz führt. Für die Frankfurter Allgemeine Zeitung, die bisher leider kein vergleichbares Visualisierungstool öffentlich anbietet, lassen sich für den Zeitraum 2014 immerhin 12 Beiträge per Archivsuche ermitteln. Für „Big Data“ übrigens 452.
Die früheste Erwähnung von „Digital Humanities“ in der New York Times datiert auf 2006. Danach gab es bis 2010 keine einzige, 2010 sechs, 2011 den bisherigen Höhepunkt mit 17. Ebenfalls 2011 hatten die Humanities ihre höchste Präsenz im Blatt seit den 1970er Jahren (283).
Kann man daraus etwas ableiten? Auf der rein quantitativen Ebene, wie sie das schöne Tool zur Echtzeitvisualisierung als Basis hat, sehr wenig. Man kann Aussagen über Konjunkturen treffen und wünschte sich, um davon mehr zu haben, als Diskursbeobachter gerade bei aktuellen Themen (zum Beispiel „Charlie Hebdo„) eine tagesgenaue Skalierbarkeit. Hilfreich wäre weiterhin eine Differenzierung der Artikelsorten (z.B. die Möglichkeit des Herausfilterns von Ankündigungen).
Man benötigt zur Deutung des Visualisierten allerdings eine ganze Menge weitere Informationen zum Beispiel zum Profil und der Geschichte der Zeitung (gerade im Vergleich mit anderen Presseerzeugnissen) oder auch zum Sprachwandel und kommt nach wie vor nicht um die Betrachtung der Beiträge selbst herum, wenn man bewerten will, wie aussagekräftig und trendspiegelnd die Zahlen tatsächlich sind.
Mehr als das ist jedoch interessant, wie sehr in Werkzeugen wie des Chronicle-Graphen die gesammte Palette der Herausforderungen des Information Retrievals deutlich werden, die die Dokumentationswissenschaft schon seit etlichen Jahrzehnten umtreiben. Was bisher – aus Sicht eines Bibliotheks- und Informationswissenschaftlers bedauerlicherweise – sehr wenig in den sich datafizierenden Geisteswissenschaften erkannt wird (oder bekannt ist), ist, wie sehr der Zweig der Dokumentationswissenschaft, aus dem die Informationswissenschaft mehr oder weniger hervorging (vgl. dazu auch: Die Big-Data-risierung des Menschen steht in der Tradition der Dokumentation und braucht Critique, meint Ronald E. Day / LIBREAS.Tumblr, 04.03.2014) sehr viele der Probleme der, wie man sagte, maschinengestützten Wissensordnung bereits sehr lange elaboriert. Je länger man sich mit den aktuellen Entwicklungen auf diesem Feld befasst und das Phänomen der „Digital Humanities“ zu verstehen versucht, desto mehr zeigt sich, wie die prädestiniert die Bibliotheks- und Informationswissenschaft für die Rolle einer systenatischen methodologischen Ausdifferenzieung digitaler Zugangs- und Analyseformen von Kulturdaten (und/oder: Diskursdaten) eigentlich ist. Klickt man sich durch die Labs wie dem der New York Times, erhält auf der anderen Seite den Eindruck, dass Tool-Innovation momentan u.a. im Journalismus stattfindet. Von Seiten der Digital Humanities diese Impulse aufzunehmen und zu integrieren ist vielleicht sogar noch schwieriger, als sich mit den Erkenntnissen der Retrievalforschung vertraut zu machen.
Der unbestreitbare Vorteil solcher Tools ist, dass man in Sekundenschnelle thematische Entwicklungen über die Zeit angedeutet als eine Art visuelle Hypothese erstellen kann. Wir werden in der Auswertung der Fu-PusH-Erhebung verschiedene Perspektiven auf das, was Digital Humanities sein können, herausarbeiten können. Eine häufige Sichtweise ist die Rolle der „Digital Humanities“ als Hilfswissenschaft. Das Beispiel deutet an, wie so etwas aussehen könnte. Daten visualisierende Frequenz- und Popularitätskurven sind in diesem Sinne durchaus eine sinnvolle Erweiterung auch für die Geisteswissenschaften. Man sollte aber auch immer um die Grenzen der Aussagekraft dieser Abbildungen wissen.