

LAUDATIO – Long-term Access and Usage of Deeply Annotated Information
Das Repositorium wurde über zwei Förderphasen der DFG entwickelt. Es verfolgt ein fachorientiertes Konzept, das anhand von linguistisch annotierten historischen Korpora entwickelt wurde, künftig aber auch für weitere textbasierte Repositorien nachgenutzt werden soll.
Der Grundgedanke ist die Trennung von abgelegten Inhalten und ihrer formalen Beschreibung für maximale wissenschaftliche Flexibilität: Die Korpora werden methodenoffen je nach Forschungsrichtung in den jeweils bevorzugten technischen Formaten abgelegt. Die fachbezogenen Metadaten mit der inhaltlichen Beschreibung der enthaltenen Daten haben jedoch ein vom jeweiligen Repositorium definiertes einheitliches Format – auf dieser Basis wird dann automatisch ein facettierter Katalog erzeugt. In der gegenwärtigen korpusorientierten Umsetzung werden drei Ebenen von Metadaten modelliert:
das Korpus als Gesamtheit aller zugehörigen Texte, der einzelne Text sowie die Typen von Annotationen, mit denen die Textteile markiert sind.
Eine besondere Herausforderung war, diesen Katalog nutzerorientiert darzustellen und in einer modernen Oberfläche verschiedene Herangehensweisen je nach Kontext und wissenschaftlicher Fragestellung zu ermöglichen. Hierbei haben wir mit einer externen Beratung UX-Verfahren eingesetzt (User Experience). Entsprechend komplex sind auch die technischen Anforderungen an die Suchmöglichkeiten, die auf Basis von Elasticsearch umgesetzt wurden. Die Textdaten werden im Backend mit GitLab verwaltet.
Im Sommer 2019 ging der Prototyp online, für 2020 sind Optimierungen und die Öffnung für weitere Disziplinen geplant, denn sowohl Datentypen als auch Metadatenstrukturen sind flexibel angelegt.
https://www.laudatio-repository.org
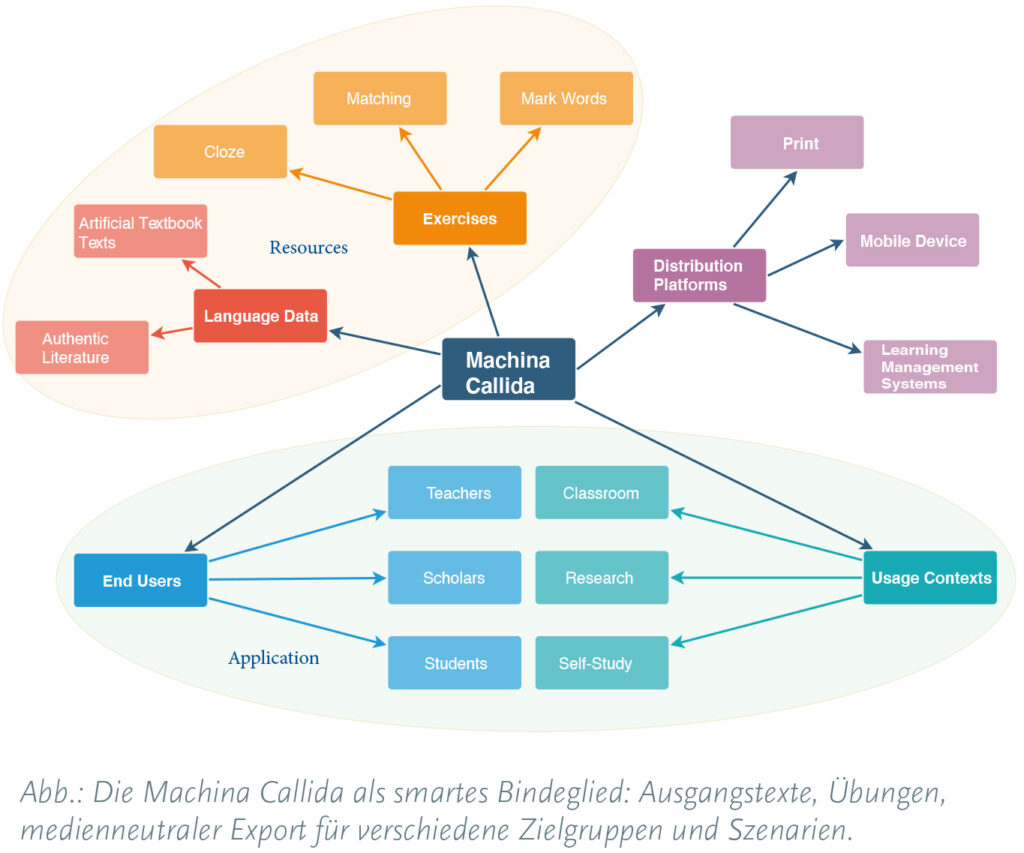
CALLIDUS – Computer-Aided Language Learning: Lexikonerwerb im Lateinunterricht durch korpusgestützte Methoden
Das interdisziplinäre Forschungsprojekt bringt drei Kompetenzbereiche zusammen: den Computer- und Medienservice, die Fachdidaktik Latein und
die Korpuslinguistik. Mit Förderung der DFG werden auf Basis tief annotierter lateinischer Korpora didaktische und technische Methoden entwickelt, die jenseits von traditionellen Vorgehensweisen im Lateinunterricht liegen. „Context matters“: Technisches Herzstück ist die Machina Callida (die „smarte Maschine“), die didaktisch geleitet eine korpusbasierte Wortschatzarbeit in der Lektürephase des Lateinunterrichts unterstützt. Sie bietet Zugriff auf zahlreiche bekannte und weniger bekannte lateinische Korpora, um für ausgewählte Textstellen Übungen zu generieren. Die Devise ist: Keine Übung ohne einen Bezug zum Kontext des Wortes, wie schon der englische Linguist John Rupert Firth 1957 schrieb: „You shall know a word by the company it keeps.“ Die Machina erstellt vielfältige Übungen aus den Korpora von Cicero, Ovid und Co.
und ermöglicht auch Auswertungen nach linguistischen und sprachdidaktischen Kriterien. Im geplanten Folgeprojekt sollen die Möglichkeiten der linguistisch fundierten Korpusanalyse mit Techniken des maschinellen Lernens ausgebaut werden. Hier wird der Fokus dann auf Werkzeugen mit speziell auf die alten Texte zugeschnittenen KI-Modellierungen für die Forschung der Klassischen Philologie liegen.
Projektinformationen: https://hu.berlin/callidus
Machina Callida: https://korpling.org/mc